Программный коррелятор RASFX
В ИПА РАН создан коррелятор для центра корреляционной обработки РСДБ-наблюдений РАН (Коррелятор RASFX). Коррелятор предназначен для обработки радиоинтерферометрических наблюдений радиотелескопов РТ-13 комплекса «Квазар-КВО». На таких радиотелескопах сигналы внегалактических источников (квазаров) регистрируются с широкой полосой пропускания частотных каналов – до 512 МГц. Суммарный поток данных на радиотелескопе в момент регистрации достигает 16 Гбит, при регистрации сигналов в двух поляризациях четырех частотных диапазонов. Коррелятор RASFX способен в режиме квазиреального времени одновременно обрабатывать наблюдательные данные от шести обсерваторий с максимальным потоком данных на входе коррелятора 96 Гбит/с. Коррелятор является программным и реализует FX-алгоритм обработки. Решения, лежащие в основе программного FX-коррелятора РАН, изложены в работе.
Основное отличие разработанного коррелятора – использование для наиболее трудоемких вычислений (таких, как быстрое преобразования Фурье, перемножение и сложение спектров, выделение сигналов фазовой калибровки) графических процессорных устройств (GPU – graphical processing units, ГПУ), в виде графических ускорителей семейства Kepler корпорации NVIDIA.
Коррелятор в 2014 г. был установлен в ИПА РАН и с 2015 г. участвует в обработке наблюдений. Коррелятор в конце 2014 г. был протестирован на максимальную производительность. Установлено, что среднеквадратическое отклонение определения групповых задержек коррелятором составило 4.4 пс.
Получено свидетельство о метрологической аттестации программного обеспечения.

Аппаратное обеспечение
Аппаратным обеспечением коррелятора являются гибридные блейд-серверные кластеры корпорации “Т-Платформы”, которые включают в себя блейд-серверы модели V200F, серверы модели Intel R2216GZ4GCLX, сетевое оборудование, высокоскоростной рейд-массив, системы управления и синхронизации процессов, системы электропитания и охлаждения.
Блейд-серверы модели V200F содержат по два процессора Intel E5-2670 (8 ядер, тактовая частота 2.6 ГГц), по два графических ускорителя NVIDIA Tesla K20 и по 64 Гб оперативной памяти.

Между собой серверы соединены локальной сетью стандарта InfiniBand на коммутаторах Mellanox, позволяющих одновременно передавать до 56 Гбит/с между любыми двумя абонентами.
Серверы Intel R2216GZ4GCLX имеют по два процессора Intel E5-2670, по два ГПУ NVIDIA Tesla K20 и сетевые порты InfiniBand. Данные серверы предназначены для приема входных потоков данных через два порта 10 Гб Ethernet каждый и расширенную до 256 Гбайт оперативную память.
Вычислительный комплекс коррелятора, установленный в ИПА РАН, содержит 32 блейд-сервера V200F и 8 серверов Intel R2216GZ4GCLX (всего 80 CPU и 80 GPU). Он способен одновременно обрабатывать потоки данных 16 Гбит/с от каждой из 6 станций.
Программное обеспечение
Программное обеспечение коррелятора осуществляет автоматизированную обработку РСДБ-наблюдений. Обработка производится в четыре этапа.
На первом (предварительном) этапе анализируются файлы планирования сессии РСДБ-наблюдений стандарта sked или vex, создаются директории и служебные файлы для промежуточных и выходных данных, для каждой станции выполняется предвычисление геометрических задержек прихода радиосигналов на станцию относительно момента времени пересечения фронта волны сигнала центра Земли.
На втором, наиболее трудоемком этапе обработки, программное обеспечение выполняет прием входных потоков данных и вычисление кросскорреляционных спектров сигналов. Осуществляется распределенная конвейерная обработка данных. Программное обеспечение формирует программные Станционные модули (СМ), Корреляционные модули (КМ) и Управляющий модуль (УМ). Их алгоритмы работы и взаимодействие описаны в разделе Алгоритм работы программных модулей коррелятора.
При обработке данных двух поляризаций сигналы каждой поляризации одной станции коррелируются с сигналами каждой поляризации другой станции. Вычисляются 2048 отсчетов кросскорреляционных спектров, получаемое спектральное разрешение 0.25 МГц позволяет эффективно фильтровать узкополосные помехи. Соответственно 2048 отсчетов кросскорреляционной функции формируют корреляционное окно шириной 2 мкс, что позволяет в ходе обработки выполнять начальную синхронизацию потоков данных, компенсируя расхождение стандартов времени и частоты станций.
На третьем этапе обработки – “постпроцессорной обработке” – вычисляются значения групповых задержек и скорости их изменения (частоты интерференции) для всех частотных каналов всех баз. Постпроцессорное программное обеспечение работает на кластере параллельно с программным обеспечением вычисления спектров. Постпроцессорные обработка очередного скана наблюдений начинается сразу после того как он прошел второй (процессорный) этап обработки.
Завершающий четвертый этап обработки выполняется после получения групповых задержек и частот интерференции по всем сканам сессии наблюдений. Результаты корреляционной обработки – групповые задержки и скорости их изменения, ионосферные задержки, а также служебная информация, извлеченная из log-файлов управляющих компьютеров станций – записываются в выходной файл стандарта NGS и передаются в системы анализа данных для определения параметров вращения Земли, координат станций и квазаров и других параметров.
При разработке программного обеспечения коррелятора использованы средства:
- C, C++ , как основные языки программирования;
- MPI (Message Passing Interface) для разработки приложения, функционирующего на большом количестве серверов и ядер;
- CUDA (Compute Unified Device Architecture) для программирования ГПУ;
- Qt для разработки пользовательского интерфейса;
- Fortran для предвычисления задержек.
Алгоритм работы программных модулей коррелятора
Поток данных от каждой станции поступает на СМ. Станционный модуль сформирован на сервере Intel R2216GZ4GCLX и управляет двумя ГПУ и двумя ЦПУ.
Первой операцией СМ является дешифровка поступающей информации – чтение меток времени и другой служебной информации из потока данных формата VDIF или VSI устройств Mark5B.
Входной поток данных от станции может содержать сигналы 4 или 8 частотных каналов, оцифрованные двухбитовым квантованием. Возможен вариант, когда данные каждого частотного канала на выходе системы регистрации станции сохраняются в отдельный файл. В этом случае в СМ коррелятора данные разных частотных каналов поступают отдельными потоками, и на ГПУ СМ производится слияние потоков данных разных каналов в единый поток.
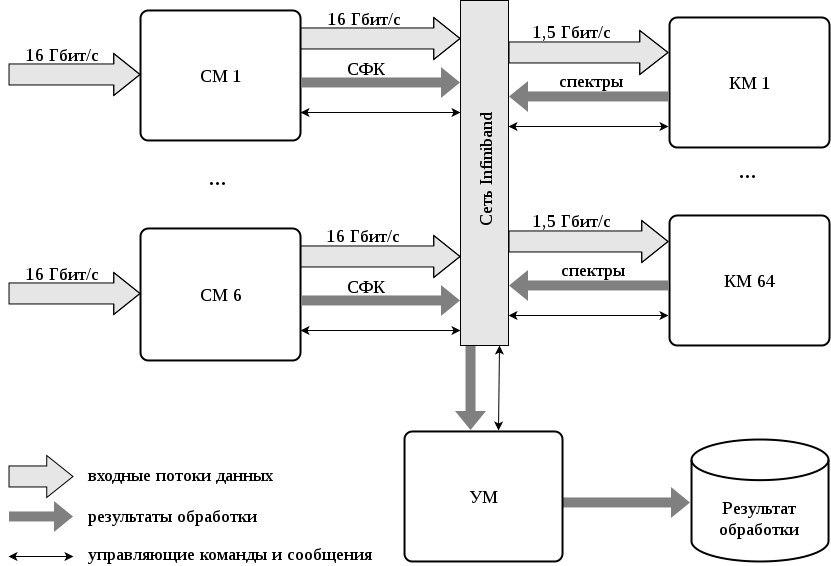
На ГПУ СМ выполняется выделение сигналов фазовой калибровки (СФК) станций по методу когерентного накопления. Далее осуществляется сопровождение РСДБ-сигналов по задержкам. В ГПУ СМ производится разделение потока данных на отдельные частотные каналы. В выходном буфере СМ накапливаются блоки данных, сопровожденных по задержке и разделенных по частотным каналам РСДБ-сигналов.
Наличие большого объема (256 Гбайт) оперативной памяти сервера СМ позволяет накапливать более 2 минут исходных данных при максимальном входном потоке 16 Гбит/c, что необходимо в случае асинхронной передачи данных от станций на коррелятор.
Через сеть стандарта InfiniBand данные со СМ распределяются на КМ таким образом, что КМ получает набор данных одного частотного канала всех станций за некоторый период времени (период накопления). В случае если наблюдения проводились в двух поляризациях и выполняется корреляция между поляризациями, КМ получает данные обеих поляризаций каждой станции.
КМ формируются на блейд-серверах V200F. Один КМ функционирует на одном ЦПУ и одном ГПУ, соответственно на блейд-сервере может функционировать два КМ. КМ принимает в оперативную память сервера данные разных станций и служебную информацию (метки времени, данные для сопровождения РСДБ-сигналов) и направляет их в ГПУ. В ГПУ исходные 2-битовые данные переводятся в 32-разрядные вещественные числа.
Синхронизация работы СМ и КМ осуществляется УМ. Он отслеживает процесс передачи данных от станций на коррелятор, выбирает сканы наблюдений готовые для обработки, осуществляет управление СМ и КМ, собирает данные выделения сигналов фазовой калибровки со СМ и спектры с КМ и сохраняет на дисках рейд-массива кластера. УМ функционирует на отдельном ядре ЦПУ кластера.
Постпроцессорное программное обеспечение
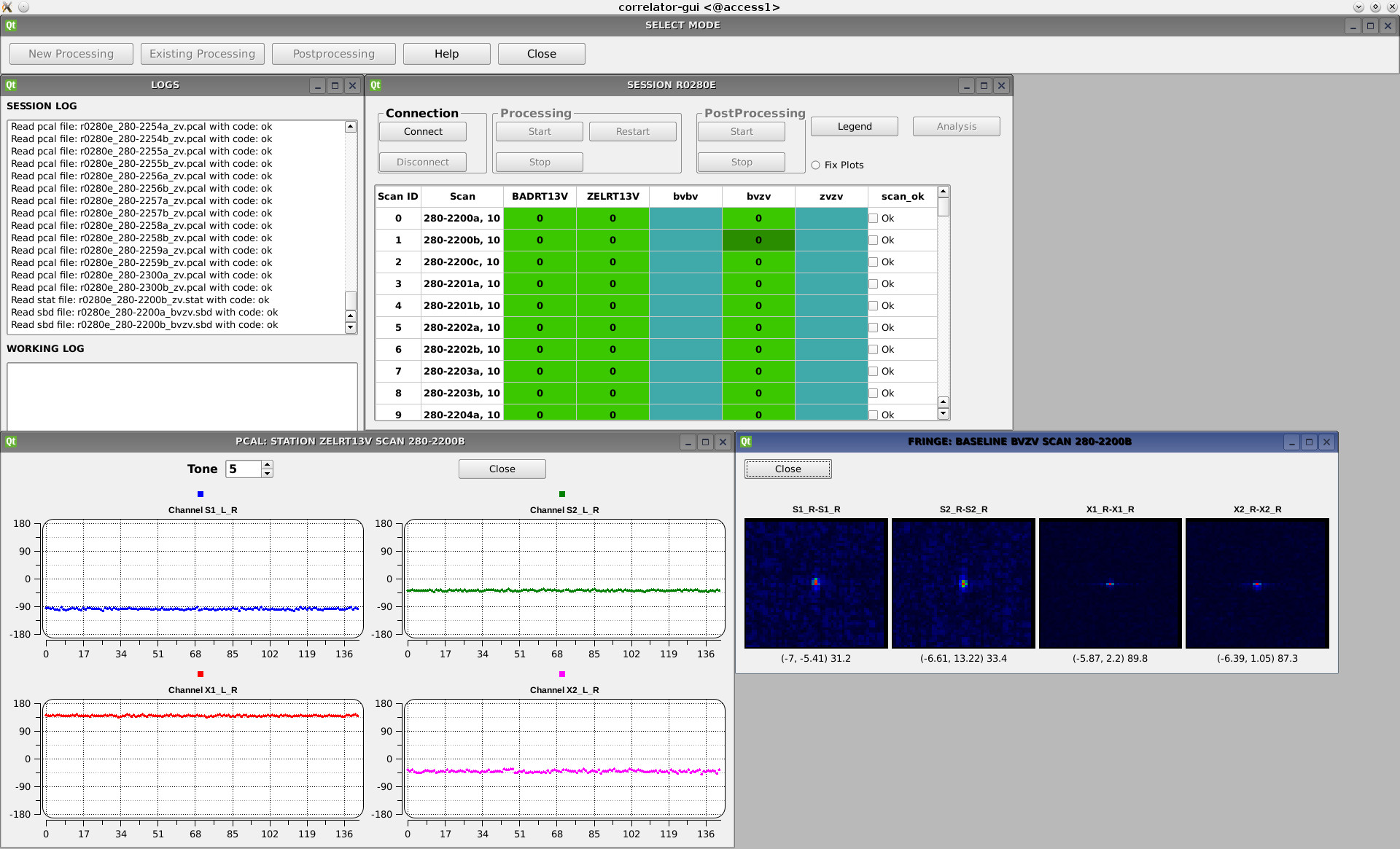
Исходными данными постпроцессорной обработки является двумерный массив кросскорреляционных спектров, вычисленных для набора периодов накопления (в наиболее часто применяемом режиме обработки вычисляется кросскорреляционный спектр из 2048 отсчетов через каждую 1/16 с). После двумерного преобразования Фурье получается массив кросскорреляционных функций от частоты интерференции. В амплитудной составляющей массива проводится поиск корреляционного отклика – пика на фоне шумовой подложки.


Завершающий четвертый этап обработки выполняется после получения групповых задержек и частот интерференции по всем сканам сессии наблюдений.
Оператор коррелятора, на завершающем четвертом этапе обработки, используя программные средства графического пользовательского интерфейса, удаляет “отскоки” (результаты обработки сканов, в которых в результате наличия помех или сбоев в работе приемно-регистрирующей аппаратуры станций сигналы сильно искажены, и полученные задержки отстоят от основного ряда).
Далее по полученным постпроцессорной обработкой групповым задержкам и частотам интерференции, фактически являющимися поправками к предвычисленным задержкам и скоростям их изменения, вычисляются полные значения задержки и скорости ее изменения.